
ما هو بيرت؟
نموذج اللغة BERT هو إطار عمل مفتوح المصدر للتعلم الآلي لمعالجة اللغة الطبيعية (البرمجة اللغوية العصبية). تم تصميم BERT لمساعدة أجهزة الكمبيوتر على فهم معنى اللغة الغامضة في النص باستخدام النص المحيط لإنشاء السياق. تم تدريب إطار عمل BERT مسبقًا باستخدام نص من ويكيبيديا ويمكن ضبطه باستخدام مجموعات بيانات الأسئلة والأجوبة.
BERT، والتي تعني تمثيلات التشفير ثنائية الاتجاه من المحولات، تعتمد على المحولات، أ تعلم عميق نموذج يتم فيه ربط كل عنصر إخراج بكل عنصر إدخال، ويتم حساب الأوزان بينهما ديناميكيًا بناءً على اتصالهما.
تاريخيًا، لم تتمكن النماذج اللغوية من قراءة النص المُدخل إلا بشكل تسلسلي – إما من اليسار إلى اليمين أو من اليمين إلى اليسار – ولكنها لم تتمكن من القيام بالأمرين معًا في نفس الوقت. يختلف BERT لأنه مصمم للقراءة في كلا الاتجاهين في وقت واحد. أدى إدخال نماذج المحولات إلى تمكين هذه الإمكانية، والتي تُعرف باسم ثنائية الاتجاه. باستخدام ثنائية الاتجاه، تم تدريب BERT مسبقًا على مهمتين مختلفتين ولكن مرتبطتين بالبرمجة اللغوية العصبية: نمذجة اللغة المقنعة (الامتيازات والرهون البحرية) والتنبؤ بالجمله التاليه (NSP).
الهدف من تدريب الامتيازات والرهون البحرية هو إخفاء كلمة في جملة ثم جعل البرنامج يتنبأ بالكلمة التي تم إخفاؤها بناءً على سياق الكلمة المخفية. الهدف من تدريب NSP هو جعل البرنامج يتنبأ بما إذا كانت جملتان معينتان لهما اتصال منطقي متسلسل أو ما إذا كانت العلاقة بينهما عشوائية ببساطة.
خلفية وتاريخ بيرت
قدمت جوجل نموذج المحول لأول مرة في عام 2017. وفي ذلك الوقت، كانت النماذج اللغوية تستخدم في المقام الأول الشبكات العصبية المتكررة (RNN) والشبكات العصبية التلافيفية (سي إن إن) للتعامل مع مهام البرمجة اللغوية العصبية.
شبكات CNN وRNNs هي نماذج مختصة، ومع ذلك، فإنها تتطلب معالجة تسلسل البيانات بترتيب ثابت. تعتبر نماذج المحولات تحسينًا كبيرًا لأنها لا تتطلب معالجة تسلسلات البيانات بأي ترتيب ثابت.
ونظرًا لأن المحولات يمكنها معالجة البيانات بأي ترتيب، فإنها تتيح التدريب على كميات أكبر من البيانات مما كان ممكنًا قبل وجودها. وقد سهّل ذلك إنشاء نماذج مدربة مسبقًا مثل BERT، والتي تم تدريبها على كميات هائلة من البيانات اللغوية قبل إصدارها.
في عام 2018، قدمت جوجل نظام BERT مفتوح المصدر. في مراحل البحث، حقق الإطار أحدث النتائج في فهم 11 لغة طبيعية (NLU) المهام، بما في ذلك تحليل المشاعر، تصنيف الأدوار الدلالية، تصنيف النص و توضيح من الكلمات ذات المعاني المتعددة. نشر الباحثون في Google AI Language تقريرًا في نفس العام يشرح هذه النتائج.
أدى إكمال هذه المهام إلى تمييز BERT عن نماذج اللغات السابقة، مثل word2vec وGloVe. وكانت تلك النماذج محدودة عند تفسير السياق والكلمات متعددة المعاني، أو الكلمات ذات المعاني المتعددة. يعالج BERT الغموض بشكل فعال، وهو التحدي الأكبر الذي يواجه NLU، وفقًا لعلماء الأبحاث في هذا المجال. إنه قادر على تحليل اللغة بحس سليم يشبه الإنسان نسبيًا.
في أكتوبر 2019، أعلنت جوجل أنها ستبدأ في تطبيق بيرت على إنتاجها في الولايات المتحدة خوارزميات البحث.
إنها مُقدَّر أن BERT يعزز فهم Google لحوالي 10% من استعلامات بحث Google باللغة الإنجليزية في الولايات المتحدة. توصي Google المؤسسات بعدم محاولة تحسين المحتوى لـ BERT، حيث يهدف BERT إلى توفير تجربة بحث طبيعية. يُنصح المستخدمون بالحفاظ على تركيز الاستعلامات والمحتوى على الموضوع الطبيعي وتجربة المستخدم الطبيعية.
بحلول ديسمبر 2019، تم تطبيق BERT على أكثر من 70 لغة مختلفة. كان للنموذج تأثير كبير على البحث الصوتي وكذلك البحث المستند إلى النص، والذي كان قبل عام 2018 عرضة للأخطاء مع تقنيات البرمجة اللغوية العصبية من Google. بمجرد تطبيق BERT على العديد من اللغات، أدى ذلك إلى تحسين تحسين محرك البحث؛ تساعده كفاءته في فهم السياق على تفسير الأنماط التي تتشاركها اللغات المختلفة دون الحاجة إلى فهم اللغة بشكل كامل.
استمر بيرت في التأثير على الكثيرين الذكاء الاصطناعي أنظمة. تم تطبيق إصدارات أخف مختلفة من BERT وأساليب تدريب مماثلة على نماذج من GPT-2 إلى ChatGPT.
كيف يعمل بيرت
الهدف من أي تقنية البرمجة اللغوية العصبية هو فهم اللغة البشرية كما يتم التحدث بها بشكل طبيعي. في حالة بيرت، هذا يعني التنبؤ بكلمة في فراغ. وللقيام بذلك، تتدرب النماذج عادةً باستخدام مستودع كبير من بيانات التدريب المتخصصة والمصنفة. تتضمن هذه العملية قيام اللغويين بعمل يدوي شاق تصنيف البيانات.
ومع ذلك، فقد تم تدريب BERT مسبقًا باستخدام مجموعة من النصوص العادية غير المُسماة، أي مجموعة ويكيبيديا الإنجليزية بأكملها ومجموعة Brown Corpus. ويستمر في التعلم من خلال تعليم غير مشرف عليه من النص غير المسمى ويتم تحسينه حتى أثناء استخدامه في التطبيقات العملية مثل بحث Google.
يعد التدريب المسبق لـ BERT بمثابة طبقة أساسية من المعرفة التي يمكنه من خلالها بناء استجاباته. من هناك، يمكن لـ BERT التكيف مع المجموعة المتزايدة باستمرار من المحتوى والاستعلامات القابلة للبحث، ويمكن ضبطه وفقًا لمواصفات المستخدم. تُعرف هذه العملية باسم نقل التعلم. وبصرف النظر عن عملية التدريب المسبق هذه، فإن BERT لديه جوانب أخرى متعددة يعتمد عليها للعمل على النحو المنشود، بما في ذلك ما يلي:
محولات
أدى عمل Google على المحولات إلى جعل مشروع BERT ممكنًا. المحول هو جزء النموذج الذي يمنح BERT قدرته المتزايدة على فهم السياق والغموض في اللغة. يقوم المحول بمعالجة أي كلمة معينة فيما يتعلق بجميع الكلمات الأخرى في الجملة، بدلاً من معالجتها واحدة تلو الأخرى. من خلال النظر إلى جميع الكلمات المحيطة، يمكّن المحول BERT من فهم السياق الكامل للكلمة وبالتالي فهم نية الباحث بشكل أفضل.
وهذا يتناقض مع الطريقة التقليدية لمعالجة اللغة، والمعروفة باسم تضمين الكلمات. تم استخدام هذا الأسلوب في نماذج مثل GloVe وword2vec. فإنه سيتم تعيين كل كلمة واحدة ل المتجهوالتي تمثل بعدًا واحدًا فقط من معنى تلك الكلمة.
نمذجة اللغة المقنعة
تتطلب نماذج تضمين الكلمات مجموعات كبيرة من البيانات البيانات المنظمة. في حين أنهم ماهرون في العديد من مهام البرمجة اللغوية العصبية العامة، إلا أنهم يفشلون في الطبيعة التنبؤية ذات السياق الثقيل للإجابة على الأسئلة لأن جميع الكلمات ثابتة إلى حد ما على ناقل أو معنى.
يستخدم BERT طريقة الامتيازات والرهونات البحرية للحفاظ على الكلمة في التركيز من رؤية نفسها، أو أن يكون لها معنى ثابت مستقل عن سياقها. يضطر BERT إلى تحديد الكلمة المقنعة بناءً على السياق وحده. في BERT، يتم تعريف الكلمات من خلال محيطها، وليس من خلال هوية مسبوقة.
آليات الاهتمام الذاتي
ويعتمد بيرت أيضًا على آلية الاهتمام الذاتي التي تلتقط وتفهم العلاقات بين الكلمات في الجملة. إن المحولات ثنائية الاتجاه الموجودة في مركز تصميم BERT تجعل هذا ممكنًا. وهذا أمر مهم لأنه في كثير من الأحيان، قد تتغير الكلمة المعنى مع تطور الجملة. كل كلمة تضاف تزيد من المعنى العام للكلمة التي تركز عليها خوارزمية البرمجة اللغوية العصبية. كلما زاد عدد الكلمات الموجودة في كل جملة أو عبارة، كلما أصبحت الكلمة محل التركيز أكثر غموضًا. يفسر BERT المعنى المعزز من خلال القراءة ثنائية الاتجاه، مع مراعاة تأثير جميع الكلمات الأخرى في الجملة على الكلمة المركزة والقضاء على الزخم من اليسار إلى اليمين الذي يتحيز الكلمات نحو معنى معين مع تقدم الجملة.
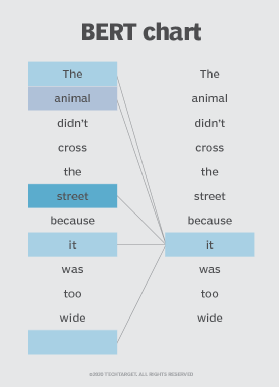
على سبيل المثال، في الصورة أعلاه، يحدد BERT الكلمة السابقة في الجملة التي تشير إليها الكلمة “it”، ثم يستخدم آلية الانتباه الذاتي لتقييم الخيارات. تعتبر الكلمة ذات أعلى الدرجات المحسوبة هي الارتباط الصحيح. في هذا المثال، تشير كلمة “it” إلى “حيوان”، وليس “شارع”. إذا كانت هذه العبارة بحثا استفسارفإن النتائج ستعكس هذا الفهم الدقيق والأكثر دقة الذي توصل إليه بيرت.
توقعات الجملة التالية
NSP هي تقنية تدريب تعلم BERT التنبؤ بما إذا كانت جملة معينة تتبع جملة سابقة لاختبار معرفته بالعلاقات بين الجمل. على وجه التحديد، يتم إعطاء BERT أزواج الجمل التي تم إقرانها بشكل صحيح والأزواج التي تم إقرانها بشكل خاطئ حتى يصبح أفضل في فهم الفرق. مع مرور الوقت، يتحسن بيرت في التنبؤ بالجمل التالية بدقة. عادة، يتم استخدام تقنيات NSP وMLM في وقت واحد.
ما هو استخدام بيرت؟
تستخدم Google BERT لتحسين تفسير استعلامات بحث المستخدم. يتفوق BERT في الوظائف التي تجعل ذلك ممكنًا، بما في ذلك ما يلي:
- مهام إنشاء اللغة تسلسل إلى تسلسل مثل:
-
- إجابة السؤال.
- تلخيص مجردة.
- التنبؤ بالجمله
- توليد الاستجابة للمحادثة.
-
- تعدد المعاني وقرار المرجع. المرجع الأساسي يعني الكلمات التي تبدو متشابهة أو تبدو متشابهة ولكن لها معاني مختلفة.
- توضيح معنى الكلمة.
- استنتاج اللغة الطبيعية.
- تصنيف المشاعر.
BERT مفتوح المصدر، مما يعني أنه يمكن لأي شخص استخدامه. تدعي Google أنه يمكن للمستخدمين تدريب نظام أسئلة وأجوبة متطور في 30 دقيقة فقط على وحدة معالجة موتر سحابي، وفي غضون ساعات قليلة باستخدام وحدة المعالجة الرسومية. تعمل العديد من المنظمات الأخرى ومجموعات البحث والفصائل المنفصلة في Google على ضبط بنية النموذج من خلال التدريب الخاضع للإشراف إما لتحسينه من أجل الكفاءة أو تخصيصه لمهام محددة عن طريق تدريب BERT مسبقًا مع تمثيلات سياقية معينة. تشمل الأمثلة ما يلي:
- براءة اختراع بيرت. تم ضبط نموذج BERT هذا بشكل دقيق لأداء مهام تصنيف براءات الاختراع.
- دوكبيرت. تم ضبط هذا النموذج بدقة لمهام تصنيف المستندات.
- بيوبيرت. نموذج تمثيل اللغة الطبية الحيوية هذا مخصص للطب الحيوي تحليل النصوص.
- فيديوبيرت. يُستخدم هذا النموذج البصري اللغوي المشترك في التعلم غير الخاضع للإشراف للبيانات غير المُصنفة على YouTube.
- سيبيرت. هذا النموذج مخصص للنص العلمي.
- جي بيرت. يستخدم نموذج BERT المُدرب مسبقًا رموزًا طبية ذات تمثيلات هرمية من خلال الشبكات العصبية الرسم البياني ومن ثم ضبطها لتقديم التوصيات الطبية.
- TinyBERT من هواوي. يتعلم بيرت “الطالب” الأصغر حجمًا من بيرت “المعلم” الأصلي، حيث يقوم بالتقطير للمحولات لتحسين الكفاءة. أنتجت TinyBERT نتائج واعدة مقارنة بقاعدة BERT بينما كانت أصغر بـ 7.5 مرة وأسرع بـ 9.4 مرة عند الاستدلال.
- DistilBERT عن طريق معانقة الوجه. يتم تدريب هذا الإصدار الأصغر والأسرع والأرخص من BERT على يد BERT، ثم تتم إزالة بعض الجوانب المعمارية لتحسين الكفاءة.
- ألبرت. يعمل هذا الإصدار الأخف من BERT على تقليل استهلاك الذاكرة وزيادة سرعة تدريب النموذج.
- سبانبيرت. أدى هذا النموذج إلى تحسين قدرة بيرت على التنبؤ بمساحات النص.
- روبرتا. ومن خلال أساليب تدريب أكثر تقدمًا، تم تدريب هذا النموذج على مجموعة بيانات أكبر لفترة أطول لتحسين الأداء.
- إلكترا. تم تصميم هذا الإصدار لإنشاء تمثيلات نصية عالية الجودة.

BERT مقابل المحولات التوليدية المدربة مسبقًا (GPT)
في حين أن نماذج BERT وGPT من بين النماذج أفضل النماذج اللغوية، فهي موجودة لأسباب مختلفة. الأولي نموذج جي بي تي-3بالإضافة إلى نماذج GPT اللاحقة الأكثر تقدمًا من OpenAI، فهي أيضًا نماذج لغوية تم تدريبها على مجموعات ضخمة من البيانات. في حين أنهم يشتركون في هذا الأمر مع بيرت، إلا أن بيرت يختلف بطرق متعددة.
بيرت
قامت Google بتطوير BERT ليكون بمثابة نموذج محول ثنائي الاتجاه يفحص الكلمات داخل النص من خلال النظر في السياقات من اليسار إلى اليمين ومن اليمين إلى اليسار. فهو يساعد أنظمة الكمبيوتر على فهم النص بدلاً من إنشاء النص، وهو ما تم تصميم نماذج GPT للقيام به. يتفوق BERT في مهام NLU بالإضافة إلى إجراء تحليل المشاعر. إنه مثالي لعمليات بحث Google وتعليقات العملاء.
جي بي تي
تختلف نماذج GPT عن BERT في أهدافها وحالات استخدامها. نماذج GPT هي أشكال من الذكاء الاصطناعي التوليدي الذي ينشئ نصًا أصليًا وأشكالًا أخرى من المحتوى. كما أنها مناسبة تمامًا لتلخيص الأجزاء الطويلة من النص والنصوص التي يصعب تفسيرها.
تختلف BERT ونماذج اللغات الأخرى ليس فقط في النطاق والتطبيقات ولكن أيضًا في الهندسة المعمارية. تعلم المزيد عن بنية GPT-3 وكيف يختلف عن بيرت.



