A variational autoencoder (VAE) is one of several generative models that use deep learning to generate new content, detect anomalies and remove noise.
VAEs first appeared in 2013, about the same time as other generative AI algorithms, such as generative adversarial networks (GANs) and diffusion models, but earlier than large language models built on BERT, the GPT family and the Pathways Language Model.
Suited for generating synthetic time series data that trains other AI algorithms, VAEs are a top choice in performing signal analysis to interpret IoT data feeds, biological signals like EEG or financial data feeds.
VAEs are also suitable for text creation, image generation and video development. However, they are more likely to complement other models such as GANs, stable diffusion — an innovation on diffusion models — and transformer models when generating different kinds of content.
VAEs combine two types of neural networks, much like GANs. However, VAEs and GANs operate differently. In the case of VAEs, one network finds better ways of encoding raw data into a latent space, while the second — the decoder — finds better ways of transforming these latent representations into new content. In GANs, one neural network finds better ways of generating fake content while the second finds better ways of detecting fake content.
What are variational autoencoders used for?
VAEs have three fundamental purposes: create new data, identify anomalies in data, and remove noisy or unwanted data. These three capabilities might not sound impressive, but they make VAEs well suited for numerous powerful applications, such as the following:
- Text creation. VAEs can generate new text about a topic in a desired style. However, the new text is limited to the scope of training text and the desired style. For example, to create a description of a baseball field in the style of Mark Twain, the training data set must include a complete description of baseball fields, along with text representative of Twain’s work.
- Image creation. VAEs can generate new images, though the images are limited by what’s available in the training data set. For example, to create an image of dogs playing poker in the style of Picasso, the training set must include pictures of dogs, poker players and images representative of Picasso’s style.
- Video creation. Similar to image creation, VAEs can produce new video sequences. Here, too, the new video elements are limited to the elements included within the training data set.
- Language processing. VAEs can recognize and understand complex relationships between data elements. This makes VAEs helpful in generating synthetic and natural-sounding speech used in chatbots, digital assistants and other AI entities.
- Anomaly detection. VAEs can process enormous volumes of data and specialize in time series or sequential data processing. This makes VAEs ideally suited to anomaly detection in data points once the benchmark or normal behavior of a system is identified.
- Synthetic data creation. Software developers use VAEs to generate synthetic data sets for software development and testing. This simplifies application development where real-world data is limited or where testing data requirements are extremely high.
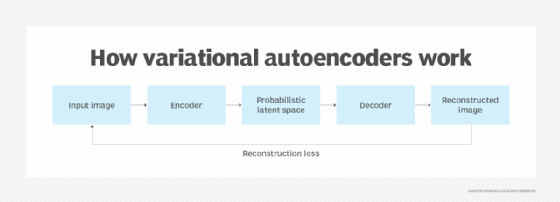
How do VAEs work?
In general, all autoencoders are a type of neural network capable of learning data. Autoencoders include both an encoder to compress input data into simpler elements and a decoder to reconstruct original data from its compressed elements. When implemented correctly, an autoencoder will reconstruct data and provide decoder output to a high degree of accuracy. As a result, the data is learned in an extremely compact manner.
A VAE adds probabilistic capabilities into the encoding process to build on the basics of an autoencoder. These probabilistic capabilities are why the term variational is added to the autoencoder terminology. In effect, a VAE can generate a broader data distribution during the encoding process and then sample from that broader data during the decoding process.
This added capability gives VAEs their generational modeling ability. It also enables VAEs to create new data that didn’t previously exist, although the new data is still representative of the training data set.
VAEs are understood through the following four basic behaviors:
- The VAE learns to identify important elements from the training data. This is the encoding behavior.
- The VAE recreates original data from the important elements of the training data. This is the decoding behavior.
- The VAE adds probabilistic capabilities, such as inference, to the encoding side, enabling the VAE to create different data outputs from the encoded samples. This is the generative mechanism.
- The VAE re-encodes those complex generative outputs back into a latent space where data is learned and encoded, which effectively lets VAEs pursue tasks such as unsupervised learning.
Types of autoencoders
There are several types of basic autoencoders beyond VAEs, including the following:
- Sparse autoencoders. These are some of the oldest and most popular approaches. They’re suitable for feature extraction, dimensionality reduction, anomaly detection and transfer learning. They use techniques to encourage the neural network to use only a subset of the intermediate neurons. This surplus of unused neurons gives them the flexibility to identify and learn a more efficient representation of data.
- Denoising autoencoders. These learn ways to reconstruct the original data from a noisy data stream. They’re often used to clean up low-light images, recognize speech and preprocess IoT data.
- Contractive autoencoders. These specialize in learning a representation that can adapt to small changes in the input data. This helps them better adapt to unseen data. Researchers highlight the most salient features in the data set responsible for results to improve the interpretability of neural network models.
- Undercomplete autoencoder. These specialize in reducing or minimizing the completeness of input data. This goal is usually accomplished by optimizing the AI model parameters and deliberately limiting the size of the encoded input, and it forces the UAE to capture only the most important elements of the input data, knowing that it might be impossible to fully recreate the original input data. UAEs are particularly useful in tasks such as data compression and anomaly detection.
- Convolutional autoencoders. These autoencoders handle complex data such as images, using convolutional layers to highlight spatial relationships and dependencies within the original data. Their ability to encode and decode complex data and to minimize the reconstruction error between input and output data elements makes these models well suited for image reconstruction, denoising, and learning.
- Conditional autoencoders. These are specialized VAEs designed to improve generative capabilities by selecting variations based on conditional information such as attributes, context or labels. Conditional VAEs are excellent choices for visualization and image generation, in which specific objects or scenes are needed, along with image-to-image translation — e.g., transforming black-and-white images into color images or converting sketches into photos. They’re also good for text generation, where prompts are used to personalize content.
Autoencoders vs. variational autoencoders
Autoencoders are an older neural network architecture that excel at automating the process of representing raw data more efficiently for various machine learning and AI applications. Plain, vanilla autoencoders are helpful in codec creation for compressing data and detecting anomalies. However, they are only useful for finding better ways to store and reconstruct the original data more efficiently.
VAEs’ key innovation is in creating a probabilistic model that can generate new content similar to — yet different from — the original content. The intermediate VAE layer provides a way to represent data in a probability field that stores more varieties with greater precision. For example, it can represent faces or images of numerical digits with smoother features. However, new content is always constrained by the scope of trained data: A VAE can’t generate data that hasn’t been learned.
Early applications of autoencoders included dimensionality reduction and feature learning. Dimensionality reduction finds a way to represent a data set more efficiently using fewer variables. Feature learning is the process of identifying the appropriate set of mathematical relationships within a data set for a particular machine learning problem.
Over the years, researchers have integrated autoencoders into other AI and machine learning algorithms to improve precision and performance. Autoencoders are suitable for image classification, object detection and noise reduction, as well as for independent component analysis applications such as filtering out one voice at a cocktail party or distilling vocals and instruments from a music track.
VAEs vs. GANs
VAEs are often compared to generative adversarial networks for their value in generative applications. However, the two models differ in their approaches to processing information and learning:
- VAEs focus on learning compressed representations of data that’s encoded and then decoded to recreate or reconstruct data. They add variational capabilities to broaden the model’s range of reconstruction options.
- GANs use an adversarial or competitive approach, where a discriminator network is trained and a generator network tries to synthesize data capable of fooling the discriminator. The discriminator and generator networks operate against each other but result in high-quality outputs such as images.
The two models aren’t mutually exclusive, and VAE-GAN hybrid models exist. The choice between the models is often based on business needs. For example, organizations that need straightforward data processing, understanding and analytics are typically better served with a VAE. Conversely, organizations seeking high-quality data generation, such as quality images, might find a GAN more useful.
How do VAEs work in neural networks?
Both VAEs and autoencoders use a reconstruction loss function to tune the neural networks using gradient descent. This optimization algorithm adjusts the weights of the neural network connections in response to feedback about the network’s performance. The algorithm rewards neural network configurations with a lower loss function since they’re more similar, while a higher loss function is penalized. This training process lets the autoencoder capture the underlying structure of and latent variables in the training data and model it into the neural network.
A traditional autoencoder represents the input data in the latent space using a regularized field of discrete numbers. In contrast, a VAE uses a probabilistic field that represents the input data in the latent space using a statistical distribution of the mean and variance of the data. The VAE also introduces a new measure called the Kullback-Leibler divergence function. The KL divergence represents differences between the learned distribution and a predetermined statistical distribution. VAEs minimize the KL divergence by maximizing the evidence lower bound, or ELBO, which is the observable input data the VAE is responsible for.
A prior distribution can be preselected from common statistical occurrences or learned from a data set. Once both VAE and autoencoders are trained, the resulting neural network can be configured into an inference engine for processing input.
In a classic standard autoencoder, the intermediate latent space signifies the input data as discrete points. It will recreate the original data when the appropriate input feeds into the inference engine. But it will fail when anomalous data is input, making it a good anomaly detector. In a VAE, slight variations in input data can generate entirely new content representative of the patterns found in the training content.
The future of VAEs
Both autoencoders and VAEs are evolving. Researchers are continuing to explore better latent space representations that promise to improve the expressiveness of the learned representations. This could enhance the performance and interpretability of autoencoders and VAEs. One example of advances in VAEs is the convolutional VAE with specific applications in generative AI.
There is also considerable research into how researchers can combine both techniques with other generative AI algorithms to improve representations of signals and patterns found in the raw data. Moreover, both techniques could play a role in data labeling or other data processing tasks to improve the training process for other AI and machine learning algorithms. As an example, the growing threat of fraud and online attacks continues to drive the development and use of VAEs toward anomaly detection applications.
Training methodologies are also improving in ways that enhance sample quality. VAEs are seeing greater integration with reinforcement learning frameworks, enabling more self-directed learning pathways. VAEs are also likely to see continued adoption in applications such as synthetic data generation, data augmentation, custom content generation and data preparation in manufacturing, energy, healthcare, finance and robotics. Future innovations might also focus on the performance and quality of VAEs for generating more types of content.
The history of autoencoders
Autoencoders trace their history back to the 1980s and research into improving neural networks. The most popular neural networks at the time — single-layer and multilayer perceptrons — used a supervised learning approach that required labeling of training data.
In the early 1990s, researchers began to explore ways to train neural networks using unlabeled data. This streamlined the development of certain applications and enabled new use cases. One line of research focused on combining neural networks for encoding and decoding data more efficiently. Researchers named these autoencoders, since they could automate the process without having to label the data.
The simplest autoencoder trained one encoder network to map input data into a compressed latent representation and a second decoder network to reconstruct the original data from the latent space. These early networks could compress and reduce noise from data.
In the early 2000s, researchers began exploring different ways of building neural networks by using more neurons in each layer to correspond to patterns in the data. Researchers called these sparse autoencoders because they required only a subset of neurons to model a representation of the data. This helped reduce overfitting, which limited the adaptability of the network to new circumstances. Sparse autoencoders also improved interpretability, since the richer network of connections made it easier to connect features in the underlying data with decisions.
Starting around 2010, researchers began to explore how they could apply deep learning approaches to craft autoencoders with multiple hidden layers, which could produce complex representations from the data. Further research explored ways to add specialized denoising autoencoders for removing noise, as well as contractive autoencoders for improving the robustness and generalizability of autoencoders.
In 2013, Diederik P. Kingma and Max Welling introduced VAE models in a paper called “Auto-Encoding Variational Bayes.” Their key innovation was to introduce variational inference to model the probability distribution of changes in the input data signal. The original paper showed how the technique could generate realistic-looking faces and handwritten numerical digits. Researchers subsequently developed various refinements on top of the new approach to improve the performance of VAEs.
It’s important to know which GenAI model to use for a specific task. Learn the techniques VAEs, GANs, diffusion, transformer and neural radiance field models use, along with their talents.




